Top 15 search engine with crawler name
What is a web crawler?
A web crawler is a digital search engine bot that uses copy and metadata to discover and index site pages. Also referred to as a spider bot, it "crawls" the world wide web (hence "spider" and "crawler") to learn what a given page is about. It then indexes the pages and stores the information for future searches.
Indexing refers to organizing data within a given schema or structure. It is a process that allows the search engine to match, with the use of indexed data, relevant search results to a query. As a result, a web crawler is a tool that facilitates web browsing.
There is a distinction between internet web crawlers and enterprise web crawlers. An internet web crawler crawls the internet and continuously expands the crawl frontier by discovering new sites and indexing them. An enterprise web crawler crawls a given business website to index site data so the information is discoverable when queried by a user using the site's search function. It can also be used as a business tool that automates certain searches.

A web crawler is a digital search engine bot that uses copy and metadata to discover and index site pages. Also referred to as a spider bot, it "crawls" the world wide web (hence "spider" and "crawler") to learn what a given page is about. It then indexes the pages and stores the information for future searches.
Indexing refers to organizing data within a given schema or structure. It is a process that allows the search engine to match, with the use of indexed data, relevant search results to a query. As a result, a web crawler is a tool that facilitates web browsing.
There is a distinction between internet web crawlers and enterprise web crawlers. An internet web crawler crawls the internet and continuously expands the crawl frontier by discovering new sites and indexing them. An enterprise web crawler crawls a given business website to index site data so the information is discoverable when queried by a user using the site's search function. It can also be used as a business tool that automates certain searches.
📊 Summary Table
# Search Engine Crawler Name Key Feature 1 Google Googlebot World's largest, AI-powered search 2 Bing Bingbot Powers Yahoo, AI-integrated 3 Yahoo! Bingbot / Slurp Bing-powered UI layer 4 Yandex YandexBot Russia’s top search engine 5 Baidu Baiduspider China’s largest, censorship-compliant 6 DuckDuckGo DuckDuckBot Privacy-focused, no tracking 7 Brave Search Bravebot Independent index, privacy-first 8 Ecosia EcosiaBot Eco-conscious, Bing-enhanced 9 Qwant Qwantify French, privacy-first, EU-based 10 Neeva (closed) Neevabot Ad-free, subscription model 11 You.com YouBot AI/Dev search with apps 12 Mojeek MojeekBot Independent crawler, privacy-centered 13 Sogou Sogou Spider Chinese engine with advanced input tech 14 Seznam SeznamBot Czech language focus 15 Swisscows SwisscowsBot Semantic search, no tracking
| # | Search Engine | Crawler Name | Key Feature |
|---|---|---|---|
| 1 | Googlebot | World's largest, AI-powered search | |
| 2 | Bing | Bingbot | Powers Yahoo, AI-integrated |
| 3 | Yahoo! | Bingbot / Slurp | Bing-powered UI layer |
| 4 | Yandex | YandexBot | Russia’s top search engine |
| 5 | Baidu | Baiduspider | China’s largest, censorship-compliant |
| 6 | DuckDuckGo | DuckDuckBot | Privacy-focused, no tracking |
| 7 | Brave Search | Bravebot | Independent index, privacy-first |
| 8 | Ecosia | EcosiaBot | Eco-conscious, Bing-enhanced |
| 9 | Qwant | Qwantify | French, privacy-first, EU-based |
| 10 | Neeva (closed) | Neevabot | Ad-free, subscription model |
| 11 | You.com | YouBot | AI/Dev search with apps |
| 12 | Mojeek | MojeekBot | Independent crawler, privacy-centered |
| 13 | Sogou | Sogou Spider | Chinese engine with advanced input tech |
| 14 | Seznam | SeznamBot | Czech language focus |
| 15 | Swisscows | SwisscowsBot | Semantic search, no tracking |
Top 15 Search Engines with Crawlers
Why is web crawling important?
Thanks to the digital revolution, the total amount of data on the web has increased. Global data generation is anticipated to increase to more than 180 zettabytes over the following two years, up until 2025. According to IDC, 80% of worldwide data will be unstructured by 2025.
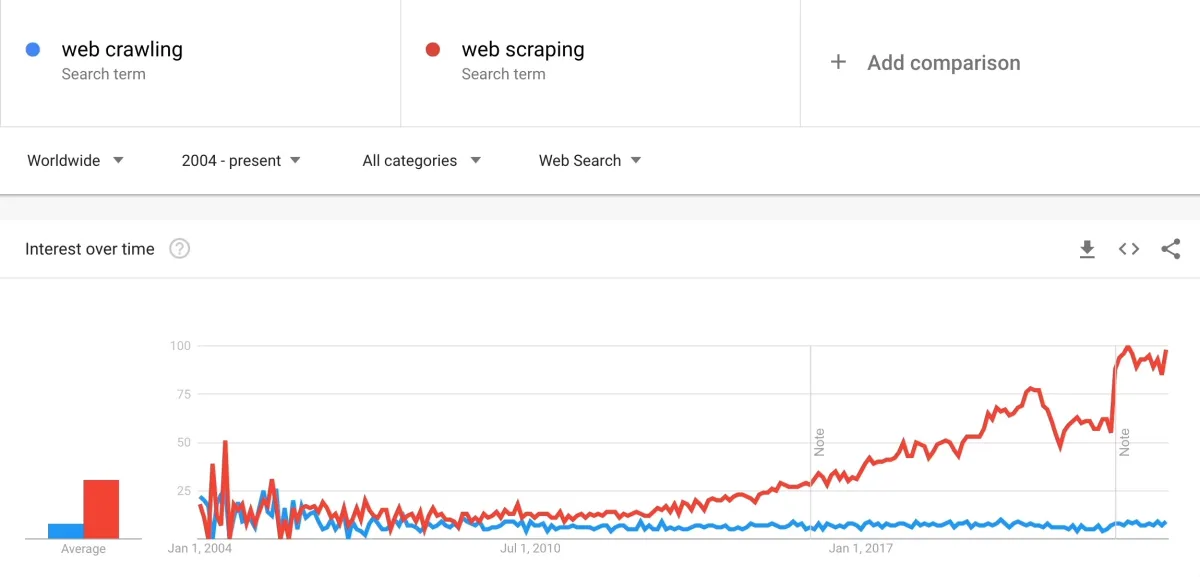
the same time period, interest in web scraping has outpaced the interest in web crawling. Possible reasons are:
1. Google
Crawler Name: Googlebot

Website: https://www.google.com
Details:
Crawler Name: Googlebot
Website: https://www.google.com
Details:
Google dominates the global search market with over 90% share.
Uses AI and machine learning in its RankBrain algorithm.
Googlebot is used to crawl webpages for both desktop and mobile versions
Supports modern technologies like JavaScript rendering, mobile-first indexing, and structured data parsing.
2. Bing (Microsoft)
Crawler Name: Bingbot

Website: https://www.bing.com
Details:
Crawler Name: Bingbot
Website: https://www.bing.com
Details:
The second-largest global search engine.
Powers other search engines like Yahoo and DuckDuckGo (sometimes).
Bingbot supports JSON-LD, schema.org, and sitemaps.
Integrates with Microsoft Edge and Cortana.
3. Yahoo!
Crawler Name: Yahoo! Slurp (legacy), now uses Bingbot 
Website: https://search.yahoo.com
Details:
Website: https://search.yahoo.com
Details:
Former major search engine, now powered by Bing.
Previously had its own crawler (Slurp), which has now been mostly retired.
Uses Bing's infrastructure, but adds its own UI layer and features.
4. Yandex (Russia)
Crawler Name: YandexBot

Website: https://www.yandex.com
Details:
Crawler Name: YandexBot
Website: https://www.yandex.com
Details:
Russia's largest search engine, also popular in Eastern Europe.
Understands Russian language morphology and grammar better than Google.
YandexBot includes versions for desktop, mobile, and media content.
5. Baidu (China)
Crawler Name: Baiduspider

Website: https://www.baidu.com
Details:
Crawler Name: Baiduspider
Website: https://www.baidu.com
Details:
China’s largest search engine, dominating more than 70% of the market there.
Focuses on Chinese language, content filtering, and censorship compliance.
Baiduspider is aggressive and crawls frequently; supports sitemaps and robots.txt.
Often slow to index non-Chinese content.
6. DuckDuckGo
Crawler Name: DuckDuckBot 
Website: https://duckduckgo.com
Details:
Website: https://duckduckgo.com
Details:
Focuses on privacy—does not track users or store personal data.
DuckDuckBot is their crawler, but it also pulls data from Bing, Yandex, Wikipedia, and more.
Offers bangs (!) feature for quick site-specific searches.
Gaining popularity for privacy-conscious users.
7. Brave Search
Crawler Name: Bravebot 
Website: https://search.brave.com
Details:
Website: https://search.brave.com
Details:
Developed by the Brave Browser team.
Fully independent index, not reliant on Google or Bing.
Bravebot respects privacy and provides ad-free, tracker-free search experience.
Gaining popularity among crypto and open-web advocates.
8. Ecosia
Crawler Name: EcosiaBot (uses Bing too) 
Website: https://www.ecosia.org
Details:
Website: https://www.ecosia.org
Details:
An eco-friendly search engine that uses profits to plant trees.
Uses Bing results combined with their own ranking system.
Has a custom crawler (EcosiaBot) for specific indexing.
Claims to have funded over 180 million trees worldwide.
9. Qwant
Crawler Name: Qwantify

Website: https://www.qwant.com
Details:
Crawler Name: Qwantify
Website: https://www.qwant.com
Details:
A French privacy-focused search engine.
Doesn’t track users or filter results by profile.
Qwantify is their own bot, but also pulls in some Bing results.
Popular in Europe, especially France and Germany.
10. NeevaAI (Neeva - Discontinued as public search but relevant historically)
Crawler Name: Neevabot 
Website: Formerly https://neeva.com
Details:
Website: Formerly https://neeva.com
Details:
Was a subscription-based search engine focused on no ads, no trackers.
Neevabot crawled independently, with AI-based summarization.
Acquired by Snowflake in 2023; still influences enterprise search tools.
11. You.com
Crawler Name: YouBot 
Website: https://you.com
Details:
Website: https://you.com
Details:
AI-powered, developer-friendly search engine.
YouBot is their crawler; combines search with apps, AI tools, code help, and summaries.
Built for developers, students, researchers
Has YouChat, a built-in AI chat like ChatGPT.
12. Mojeek
Crawler Name: MojeekBot 
Website: https://www.mojeek.com
Details:
Website: https://www.mojeek.com
Details:
Independent search engine with its own index (not Bing or Google).
Focuses on privacy and unbiased search.
MojeekBot crawls billions of pages; based in the UK.
Ideal for alternative and academic searches.
13. Sogou (China)
Crawler Name: Sogou Spider

Website: https://www.sogou.com
Details:
Crawler Name: Sogou Spider
Website: https://www.sogou.com
Details:
One of the top Chinese-language search engines.
Sogou Spider crawls web, news, images, and translation content.
Supports voice and handwriting search, especially via Chinese input methods.
Bought by Tencent in 2021.
14. Seznam (Czech Republic)
Crawler Name: SeznamBot 
Website: https://www.seznam.cz
Details:
Website: https://www.seznam.cz
Details:
Most popular search engine in Czech Republic.
Offers search for web, news, video, images, maps.
SeznamBot focuses on Czech-language content.
Built for local indexing and regional language support.
15. Swisscows
Crawler Name: SwisscowsBot
Website: https://swisscows.com
Details:
Website: https://swisscows.com
Details:


Comments
Post a Comment